Flink quick start 初探索
· 4 min read

Flink quick start 初探索(windows)
1.环境搭建
https://flink.apache.org/ 到flink 官网下载flink 安装包 这里下载的是1.6 binaries 依赖库
解压至windows 任意目录 直接运行 bin 目录下的 start-cluster.bat
这里对flink的初步印象 环境方面 local方式简单 无需配置 比较人性化 然后 webui 是8081端口 http://localhost:8081 web端页面比较友好可以直接通过web端提交任务 任务的各个运行步骤解析也比较全
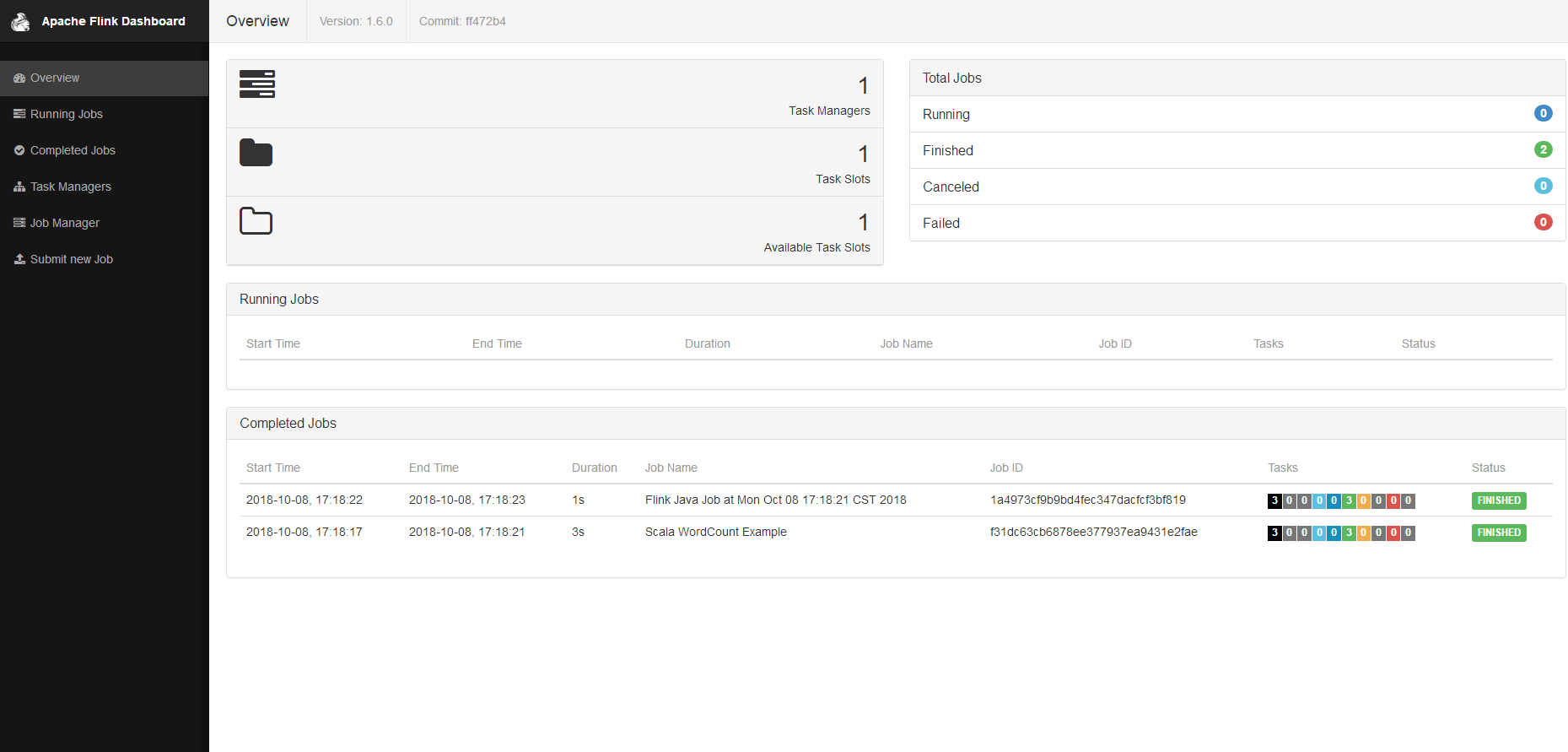
这里 环境搭建就结束了
2.本地开发
这里我使用的是scala api 开发 首先idea 创建maven 项目 在pom 加入依赖包 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wxstc.dl.fink</groupId>
<artifactId>Learn</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- java dependencies-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.0</version>
<scope>provided</scope>
</dependency>
<!-- scala dependencies -->
<!--<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.0</version>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.6.0</version>
<scope>provided</scope>
</dependency>
<!-- kafka connector 注意第三方包 flink核心依赖内不内置需要打入自己jar 内-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!--<arg>-make:transitive</arg>-->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.wxstc.dl.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
然后是代码部分
package com.wxstc.dl
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
//获取env 环境 也就是flink 环境信息 类似于spark context
val env = ExecutionEnvironment.getExecutionEnvironment
val outputPath = "D:\\_vm\\finkoutput"
val text = env.readTextFile("D:\\_vm\\finkinput\\123.txt")
val counts = text.flatMap { _.toLowerCase.split(",") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
counts.writeAsCsv(outputPath, "\n", " ")
//一定要加上这句 代表执行job 类似于 spark start
env.execute("Scala WordCount Example")
counts.print()
}
}
3.打包上传运行
通过maven package 打包 通过flink bin目录命令上传运行
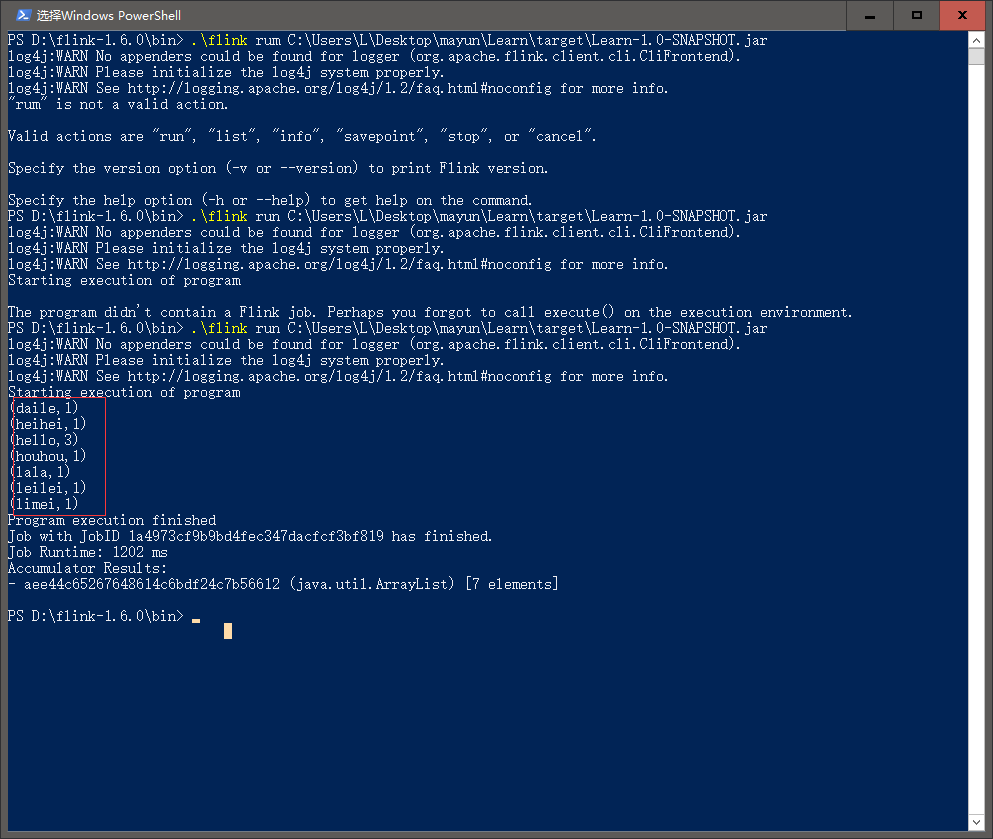
这里flink的简单demo 完毕 后续继续学习flink的优势之初 以及和spark streaming进行对比。
4.本地运行调试
如果想像spark 一样单机 以local 的模式运行可以在pom中加入
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.6.0</version>
<!--<scope>provided</scope>-->
</dependency>
然后代码中ExecutionEnvironment 获取为
val env = ExecutionEnvironment.createLocalEnvironment(5); 5为并行化线程数