spark 数据本地性级别

spark 数据本地性级别
数据本地性对Spark作业往往会有较大的影响。如果代码和其所操作的数据在同一节点上,那么计算速度肯定会更快一些。 但如果二者不在一起,那必然需要移动其中之一。一般来说,移动序列化好的代码肯定比挪动一大堆数据要快。Spark就是基于这个一般性原则来构建数据本地性的调度。
数据本地性是指代码和其所处理的数据的距离。基于数据当前的位置,数据本地性可以划分成以下几个层次(按从近到远排序):
-
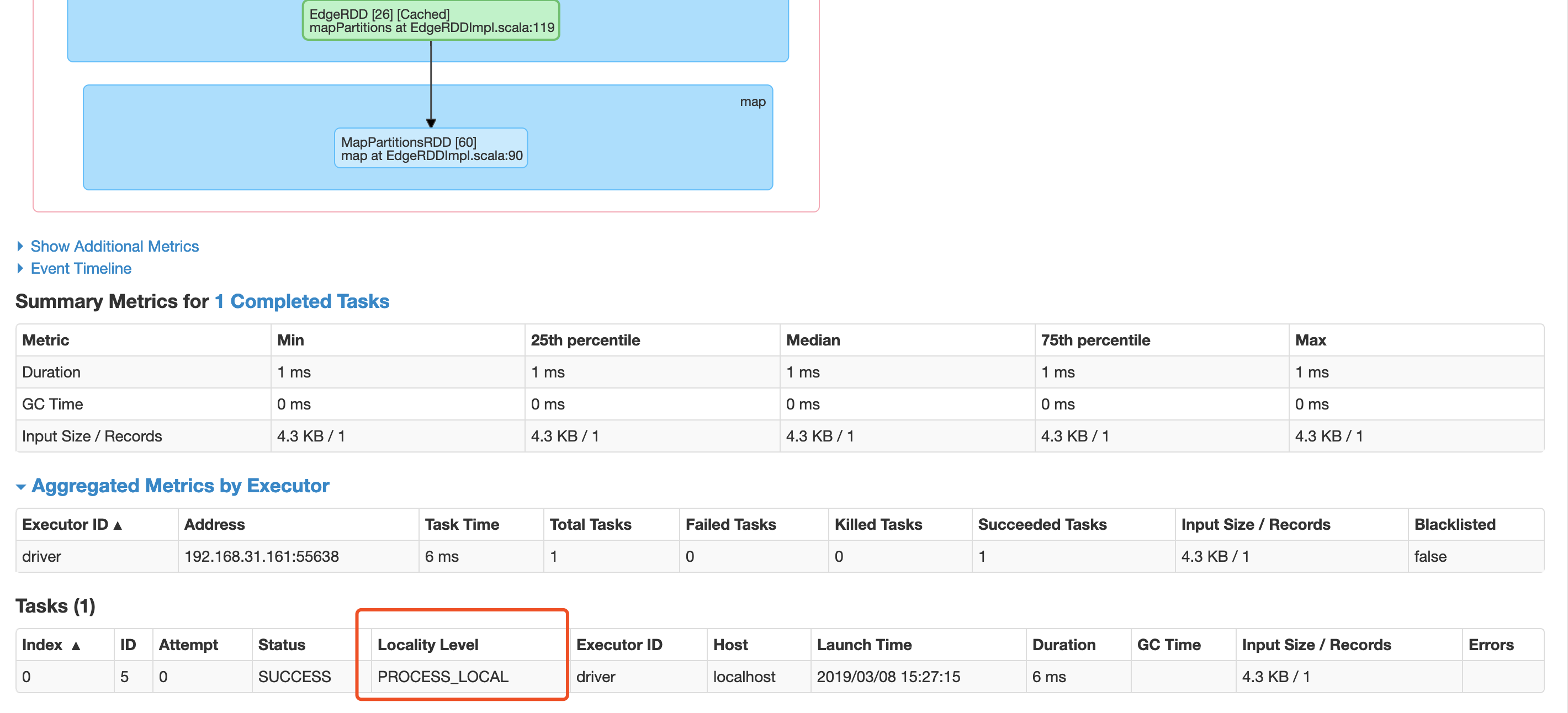
PROCESS_LOCAL 数据和运行的代码处于同一个JVM进程内。
-
NODE_LOCAL 数据和代码处于同一节点。例如,数据处于HDFS上某个节点,而对应的执行器(executor)也在同一个机器节点上。这会比PROCESS_LOCAL稍微慢一些,因为数据需要跨进程传递。
-
NO_PREF 数据在任何地方处理都一样,没有本地性偏好。
-
RACK_LOCAL 数据和代码处于同一个机架上的不同机器。这时,数据和代码处于不同机器上,需要通过网络传递,但还是在同一个机架上,一般也就通过一个交换机传输即可。
-
ANY 数据在网络中未知,即数据和代码不在同一个机架上。
Spark倾向于让所有任务都具有最佳的数据本地性,但这并非总是可行的。某些情况下,可能会出现一些空闲的执行器(executor)没有待 处理的数据,那么Spark可能就会牺牲一些数据本地性。有两种可能的选项:a)等待已经有任务的CPU,待其释放后立即在同一台机器上启动 一个任务;b)立即在其他节点上启动新任务,并把所需要的数据复制过去。
通常,Spark会等待一会,看看是否有CPU会被释放出来。一旦等待超时,则立即在其他节点上启动并将所需的数据复制过去。数据本地性 各个级别之间的回落超时可以单独配置,也可以在统一参数内一起设定;如果你的任务执行时间比较长并且数据本地性很差, 你就应该试试调大这几个参数,不过默认值一般都能适用于大多数场景了。
下面是spark web ui 中task 的data level级别信息