记录一次版本更换升级 出现错误 以及排查问题思路 与 解决方案

首先我们在使用各个组件整合的时候,版本更换时候 大部分时候会遇到问题. 今天cdh 环境从5.13 更换为6.0.1 这算是大的版本变动,hadoop基础版本 也升级成为了3.0 但是由于我们使用的自定义组件 cdh内版本较久 bug较多 所以整合方式 自己管理 然后hdp的配置文件 以及 依赖 通过手动修改配置文件 的方式由于之前cdh5 时候 cdh hadoop 版本为2.X 这次更新后 使用init 脚本时候爆出如下错误:
Failed to instantiate SLF4J LoggerFactory
Reported exception:
java.lang.NoClassDefFoundError: org/apache/log4j/Level
at org.slf4j.LoggerFactory.bind(LoggerFactory.java:150)
at org.slf4j.LoggerFactory.performInitialization(LoggerFactory.java:124)
at org.slf4j.LoggerFactory.getILoggerFactory(LoggerFactory.java:412)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:357)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:383)
at org.apache.accumulo.start.Main.<clinit>(Main.java:38)
Caused by: java.lang.ClassNotFoundException: org.apache.log4j.Level
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 6 more
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/log4j/Level
at org.slf4j.LoggerFactory.bind(LoggerFactory.java:150)
at org.slf4j.LoggerFactory.performInitialization(LoggerFactory.java:124)
at org.slf4j.LoggerFactory.getILoggerFactory(LoggerFactory.java:412)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:357)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:383)
at org.apache.accumulo.start.Main.<clinit>(Main.java:38)
Caused by: java.lang.ClassNotFoundException: org.apache.log4j.Level
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 6 more
像这种错误 第一眼 ClassNotFoundException 哪些情况会发生
1·jar包缺失(最基本的 因为没有jar 所以出现的class not found) ps:由于更换版本 所以有可能会是hdp3 以后缺少相关jar
2·jar包冲突(这也是最常见 也是比较坑的 例如 原先log4j 1.2 现在依赖更新为 1.3 很多jar更新后会废弃以前的一些method 或者 class 所以会出现这种情况)
下面是我解决这种问题的一些思路:
1.因为报错的是这个类 所以率先找个这个类所在jar包 org.apache.log4j.Level 我找jar的方式一般是 找到该框架源码 查找类名 会有maven 依赖的相关jar包版本
2.找到这个jar后基本可以确认问题的主要点
3.因为这个问题是shell 引起的所以最基本的 从 shell入口 刚开始啃shell 确实比较费力 下面贴出shell 以及我调试shell 的方法 可能比较笨
下面是shell 的内容 我更换的主要是cdh 版本 所以也就是这里面的 HADOOP_PREFIX
#! /usr/bin/env bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Start: Resolve Script Directory
SOURCE="${BASH_SOURCE[0]}"
while [ -h "${SOURCE}" ]; do # resolve $SOURCE until the file is no longer a symlink
bin="$( cd -P "$( dirname "${SOURCE}" )" && pwd )"
SOURCE="$(readlink "${SOURCE}")"
[[ "${SOURCE}" != /* ]] && SOURCE="${bin}/${SOURCE}" # if $SOURCE was a relative symlink, we need to resolve it relative to the path where the symlink file was located
done
bin="$( cd -P "$( dirname "${SOURCE}" )" && pwd )"
script=$( basename "${SOURCE}" )
# Stop: Resolve Script Directory
. "${bin}"/config.sh
START_JAR="${ACCUMULO_HOME}/lib/accumulo-start.jar"
#
# Resolve a program to its installation directory
#
locationByProgram()
{
RESULT=$( which "$1" )
if [[ "$?" != 0 && -z "${RESULT}" ]]; then
echo "Cannot find '$1' and '$2' is not set in $ACCUMULO_CONF_DIR/accumulo-env.sh"
exit 1
fi
while [ -h "${RESULT}" ]; do # resolve $RESULT until the file is no longer a symlink
DIR="$( cd -P "$( dirname "$RESULT" )" && pwd )"
RESULT="$(readlink "${RESULT}")"
[[ "${RESULT}" != /* ]] && RESULT="${DIR}/${RESULT}" # if $RESULT was a relative symlink, we need to resolve it relative to the path where the symlink file was located
done
# find the relative home directory, accounting for an extra bin directory
RESULT=$(dirname "$(dirname "${RESULT}")")
echo "Auto-set ${2} to '${RESULT}'. To suppress this message, set ${2} in conf/accumulo-env.sh"
eval "${2}=${RESULT}"
}
test -z "${JAVA_HOME}" && locationByProgram java JAVA_HOME
test -z "${HADOOP_PREFIX}" && locationByProgram hadoop HADOOP_PREFIX
test -z "${ZOOKEEPER_HOME}" && locationByProgram zkCli.sh ZOOKEEPER_HOME
DEFAULT_GENERAL_JAVA_OPTS=""
#
# ACCUMULO_XTRAJARS is where all of the commandline -add items go into for reading by accumulo.
# It also holds the JAR run with the jar command and, if possible, any items in the JAR manifest's Class-Path.
#
if [ "$1" = "-add" ] ; then
export ACCUMULO_XTRAJARS="$2"
shift 2
else
export ACCUMULO_XTRAJARS=""
fi
if [ "$1" = "jar" -a -f "$2" ] ; then
if [[ $2 =~ ^/ ]]; then
jardir="$(dirname "$2")"
jarfile="$2"
else
jardir="$(pwd)"
jarfile="${jardir}/${2}"
fi
if jar tf "$jarfile" | grep -q META-INF/MANIFEST.MF ; then
cp="$(unzip -p "$jarfile" META-INF/MANIFEST.MF | grep ^Class-Path: | sed 's/^Class-Path: *//')"
if [[ -n "$cp" ]] ; then
for j in $cp; do
if [[ "$j" != "Class-Path:" ]] ; then
ACCUMULO_XTRAJARS="${jardir}/${j},$ACCUMULO_XTRAJARS"
fi
done
fi
fi
ACCUMULO_XTRAJARS="${jarfile},$ACCUMULO_XTRAJARS"
fi
#
# Set up -D switches for JAAS and Kerberos if env variables set
#
if [[ ! -z ${ACCUMULO_JAAS_CONF} ]]; then
ACCUMULO_GENERAL_OPTS="${ACCUMULO_GENERAL_OPTS} -Djava.security.auth.login.config=${ACCUMULO_JAAS_CONF}"
fi
if [[ ! -z ${ACCUMULO_KRB5_CONF} ]]; then
ACCUMULO_GENERAL_OPTS="${ACCUMULO_GENERAL_OPTS} -Djava.security.krb5.conf=${ACCUMULO_KRB5_CONF}"
fi
#
# Add appropriate options for process type
#
case "$1" in
master) export ACCUMULO_OPTS="${ACCUMULO_GENERAL_OPTS} ${ACCUMULO_MASTER_OPTS}" ;;
gc) export ACCUMULO_OPTS="${ACCUMULO_GENERAL_OPTS} ${ACCUMULO_GC_OPTS}" ;;
tserver*) export ACCUMULO_OPTS="${ACCUMULO_GENERAL_OPTS} ${ACCUMULO_TSERVER_OPTS}" ;;
monitor) export ACCUMULO_OPTS="${ACCUMULO_GENERAL_OPTS} ${ACCUMULO_MONITOR_OPTS}" ;;
shell) export ACCUMULO_OPTS="${ACCUMULO_GENERAL_OPTS} ${ACCUMULO_SHELL_OPTS}" ;;
*) export ACCUMULO_OPTS="${ACCUMULO_GENERAL_OPTS} ${ACCUMULO_OTHER_OPTS}" ;;
esac
XML_FILES="${ACCUMULO_CONF_DIR}"
LOG4J_JAR=$(find -H "${HADOOP_PREFIX}/lib" "${HADOOP_PREFIX}"/share/hadoop/common/lib -name 'log4j*.jar' -print 2>/dev/null | head -1)
SLF4J_JARS="${ACCUMULO_HOME}/lib/slf4j-api.jar:${ACCUMULO_HOME}/lib/slf4j-log4j12.jar"
# The `find` command could fail for environmental reasons or bad configuration
# Avoid trying to run Accumulo when we can't find the jar
if [ -z "${LOG4J_JAR}" -a -z "${CLASSPATH}" ]; then
echo "Could not locate Log4j jar in Hadoop installation at \${HADOOP_PREFIX}"
exit 1
fi
CLASSPATH="${XML_FILES}:${START_JAR}:${SLF4J_JARS}:${LOG4J_JAR}:${CLASSPATH}"
if [ -z "${JAVA_HOME}" -o ! -d "${JAVA_HOME}" ]; then
echo "JAVA_HOME is not set or is not a directory. Please make sure it's set globally or in conf/accumulo-env.sh"
exit 1
fi
if [ -z "${HADOOP_PREFIX}" -o ! -d "${HADOOP_PREFIX}" ]; then
echo "HADOOP_PREFIX is not set or is not a directory. Please make sure it's set globally or in conf/accumulo-env.sh"
exit 1
fi
if [ -z "${ZOOKEEPER_HOME}" -o ! -d "${ZOOKEEPER_HOME}" ]; then
echo "ZOOKEEPER_HOME is not set or is not a directory. Please make sure it's set globally or in conf/accumulo-env.sh"
exit 1
fi
# This is default for hadoop 2.x;
# for another distribution, specify (DY)LD_LIBRARY_PATH
# explicitly in ${ACCUMULO_HOME}/conf/accumulo-env.sh
# usually something like:
# ${HADOOP_PREFIX}/lib/native/${PLATFORM}
if [ -e "${HADOOP_PREFIX}/lib/native/libhadoop.so" ]; then
LIB_PATH="${HADOOP_PREFIX}/lib/native"
LD_LIBRARY_PATH="${LIB_PATH}:${LD_LIBRARY_PATH}" # For Linux
DYLD_LIBRARY_PATH="${LIB_PATH}:${DYLD_LIBRARY_PATH}" # For Mac
fi
# Export the variables just in case they are not exported
# This makes them available to java
export JAVA_HOME HADOOP_PREFIX ZOOKEEPER_HOME LD_LIBRARY_PATH DYLD_LIBRARY_PATH
# Strip the instance from $1
APP=$1
# Avoid setting an instance unless it's necessary to ensure consistency in filenames
INSTANCE=""
# Avoid setting a pointless system property
INSTANCE_OPT=""
if [[ "$1" =~ ^tserver-[1-9][0-9]*$ ]]; then
APP="$(echo "$1" | cut -d'-' -f1)"
# Appending the trailing underscore to make single-tserver deploys look how they did
INSTANCE="$(echo "$1" | cut -d'-' -f2)_"
#Rewrite the input arguments
set -- "$APP" "${@:2}"
# The extra system property we'll pass to the java cmd
INSTANCE_OPT="-Daccumulo.service.instance=${INSTANCE}"
fi
#
# app isn't used anywhere, but it makes the process easier to spot when ps/top/snmp truncate the command line
JAVA="${JAVA_HOME}/bin/java"
exec "$JAVA" "-Dapp=$1" \
$INSTANCE_OPT \
$ACCUMULO_OPTS \
-classpath "${CLASSPATH}" \
-XX:OnOutOfMemoryError="${ACCUMULO_KILL_CMD:-kill -9 %p}" \
-XX:-OmitStackTraceInFastThrow \
-Djavax.xml.parsers.DocumentBuilderFactory=com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl \
-Dorg.apache.accumulo.core.home.dir="${ACCUMULO_HOME}" \
-Dhadoop.home.dir="${HADOOP_PREFIX}" \
-Dzookeeper.home.dir="${ZOOKEEPER_HOME}" \
org.apache.accumulo.start.Main \
"$@"
在看这种复杂shell 的时候 在linux 的vim 中使用 /HADOOP_PREFIX 关键字搜索文档中出现的位置 然后逐步分析
在shell 最后 exec 是在执行 java程序 也就是我允许的 init 过程 包的错 说明在最后运行的时候肯定class path 跟以前不一样 导致的jar 缺失
在shell 中可以通过 echo 来打印输出 从而达到debug的 目的 这时候打印的信息如下
JAVA="${JAVA_HOME}/bin/java"
#加入自己调试信息
echo "runtime classpath ${CLASSPATH}"
exec "$JAVA" "-Dapp=$1" \
$INSTANCE_OPT \
$ACCUMULO_OPTS \
-classpath "${CLASSPATH}" \
-XX:OnOutOfMemoryError="${ACCUMULO_KILL_CMD:-kill -9 %p}" \
-XX:-OmitStackTraceInFastThrow \
-Djavax.xml.parsers.DocumentBuilderFactory=com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl \
-Dorg.apache.accumulo.core.home.dir="${ACCUMULO_HOME}" \
-Dhadoop.home.dir="${HADOOP_PREFIX}" \
-Dzookeeper.home.dir="${ZOOKEEPER_HOME}" \
org.apache.accumulo.start.Main \
"$@"
runtime classpath /usr/local/accumulo-1.9.2/conf:/usr/local/accumulo-1.9.2/lib/accumulo-start.jar:/usr/local/accumulo-1.9.2/lib/slf4j-api.jar:/usr/local/accumulo-1.9.2/lib/slf4j-log4j12.jar:/opt/cloudera/parcels/CDH/lib/hadoop/lib/log4j-core-2.8.2.jar:.:/usr/java/jdk1.8.0_151/lib:/usr/java/jdk1.8.0_151/jre/lib:
找到了 程序runtime 的class path 就很好分析了 上千找的log4j的maven 中引用依赖是 log4j-1.27.jar 在运行class path中并没有找到而是变成了log4j-core所以继续在shell中寻找 信息
LOG4J_JAR=$(find -H "${HADOOP_PREFIX}/lib" "${HADOOP_PREFIX}"/share/hadoop/common/lib -name 'log4j*.jar' -print 2>/dev/null | head -1)
这段大概就是去 HADOOP_PREFIX 中寻找log4j jar 用的find 的shell 取第一个 于是到相关目录下 寻找相关jar包 如图
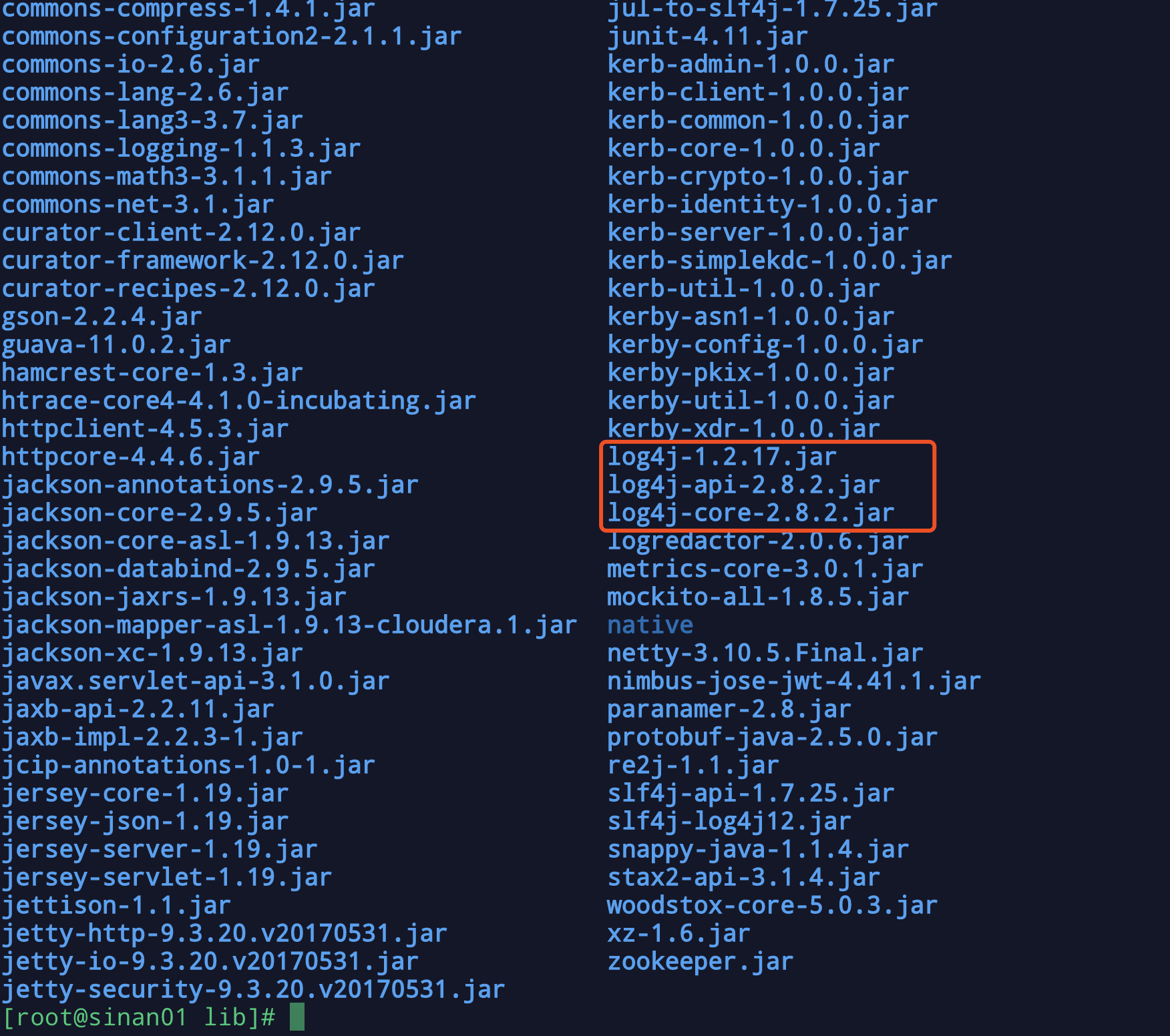
有三个符合条件的 于是运行那条shell 结果
find -H /opt/cloudera/parcels/CDH/lib/hadoop/lib /opt/cloudera/parcels/CDH/lib/hadoop/share/hadoop/common/lib -name 'log4j*.jar' -print 2>/dev/null | head -1
/opt/cloudera/parcels/CDH/lib/hadoop/lib/log4j-core-2.8.2.jar
显而易见 因为数据库初始化脚本中的 shell 查找到的jar包不正常导致的 更改为
LOG4J_JAR=$(find -H "${HADOOP_PREFIX}/lib" "${HADOOP_PREFIX}"/share/hadoop/common/lib -name 'log4j-1.*.jar' -print 2>/dev/null | head -1)
问题解决
已经在accumulo githup 提交patch 并且更新到1.9.3版本中