JDK1.7 与 JDK1.8 ConcurrentHashMap 实现方式总结 对比
· 4 min read

JDK1.7 ConcurrentHashMap
ConcurrentHashMap是Java 5中支持高并发、高吞吐量的线程安全HashMap实现。
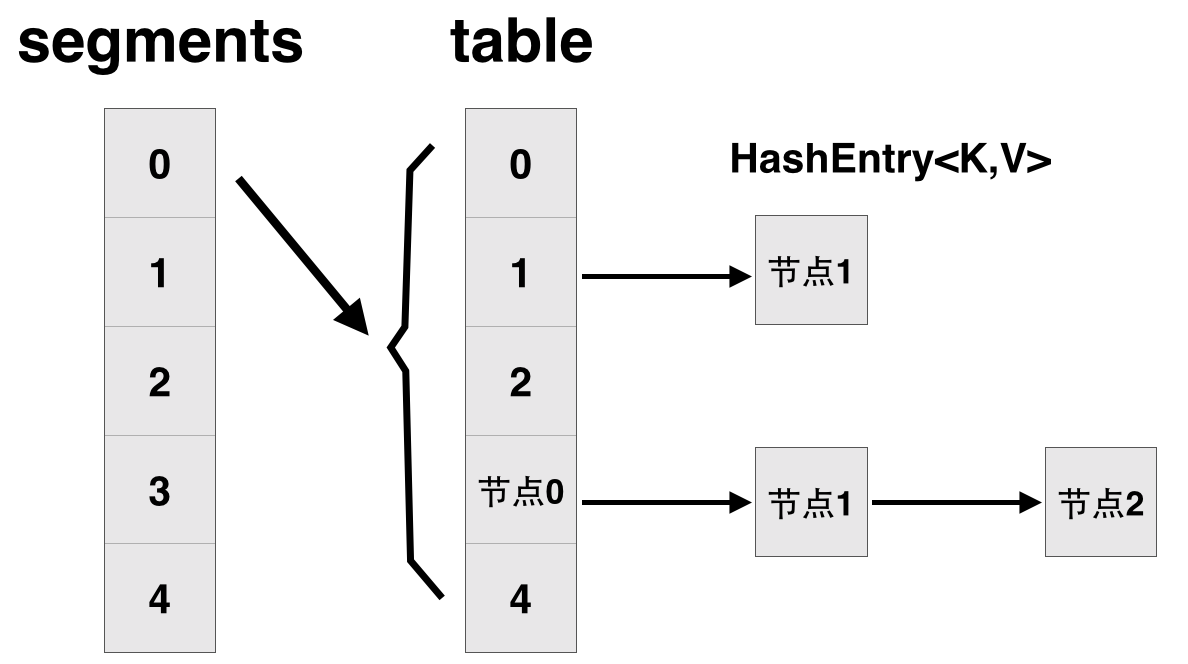
简单表述一下 jdk7 的 ConcurrentHashMap segment 分段 HashEntry<K,V>[] table 所以只要并发操作不在同一个segment 上 就可以并发执行
ConcurrentHashMap是一个支持高并发的高性能的HashMap实现,它支持完全并发的读以及一定程度并发的写。
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// 将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put, remove等操作,可以减少并发冲突,对
// 不属于同一个片段的节点可以并发操作,大大提高了性能
final Segment<K,V>[] segments;
// 本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock, 可以作为互拆锁使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// 基本节点,存储Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}
JDK1.8 ConcurrentHashMap
改进
- 取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
- 将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果table为空,初始化;否则,根据hash值计算得到数组索引i,如果tab[i]为空,直接新建节点Node即可。注:tab[i]实质为链表或者红黑树的首节点。
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果tab[i]不为空并且hash值为MOVED,说明该链表正在进行transfer操作,返回扩容完成后的table。
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 针对首个节点进行加锁操作,而不是segment,进一步减少线程冲突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在链表中找到值为key的节点e,直接设置e.val = value即可。
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果没有找到值为key的节点,直接新建Node并加入链表即可。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果首节点为TreeBin类型,说明为红黑树结构,执行putTreeVal操作。
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果节点数>=8,那么转换链表结构为红黑树结构。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 计数增加1,有可能触发transfer操作(扩容)。
addCount(1L, binCount);
return null;
}